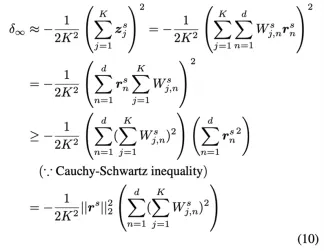Abstract
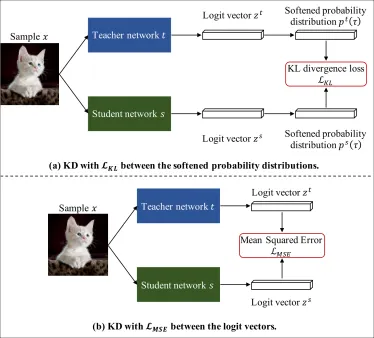
Knowledge distillation (KD), transferring knowledge from a cumbersome teacher model to a lightweight student model, has been investigated to design efficient neural architectures. Generally, the objective function of KD is the Kullback-Leibler (KL) divergence loss between the softened probability distributions of the teacher model and the student model with the temperature scaling hyperparameter τ . Despite its widespread use, few studies have discussed the influence of such softening on generalization. Here, we theoretically show that the KL divergence loss focuses on the logit matching when τ increases and the label matching when τ goes to 0 and empirically show that the logit matching is positively correlated to performance
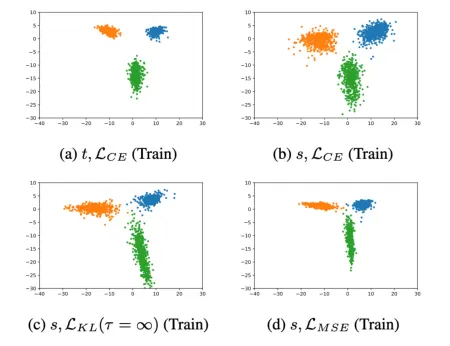
improvement in general. From this observation, we consider an intuitive KD loss function, the mean squared error (MSE) between the logit vectors, so that the student model can directly learn the logit of the teacher model. The MSE loss outperforms the KL divergence loss, explained by the difference in the penultimate layer representations between the two losses. Furthermore, we show that sequential distillation can improve performance and that KD, particularly when using the KL divergence loss with small τ , mitigates the label noise. The code to reproduce the experiments is publicly available online at https://github.com/jhoon-oh/kd data/.
Experimental Results

수식. KL Divergence 극한값 변화
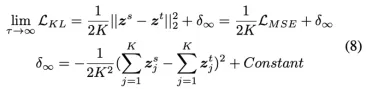
수식. KL Divergence와 MSE Loss의 관계